Stammbaum aller Kettenreaktionen
Dies ist ein Gastbeitrag vom User rkschlotte zum Thema Kettenreaktionscaches, vielen Dank dafür!
Vorgeschichte
mic@ erzählte mir von seiner Idee, den “Stammbaum” der Kettenreaktionscaches zu ermitteln und aufzumalen. Diese Cacheserie besitzt folgende drei Regeln:
a) Du mußt Dich ins Logbuch eintragen.
b) Du mußt die Kettenreaktion in Gang halten durch Legen eines weiteren Caches
namens “Kettenreaktion (Owner)”. Verweise bitte per Link auf Deinen neuen Cache.c) Die Art und Größe des neuen Caches ist gänzlich Dir überlassen.
Wichtig ist nur, daß die gelb unterlegte Cachebeschreibung mit Bild exakt 1:1 übernommen wird,
damit alle Kettenreaktion-Caches denselben Aufbau haben.
Da jeder Finder aufgefordert wird, gleichzeitig Owner eines neuen Caches zu werden, lässt sich aus dieser Abfolge wunderbar ein Stammbaum erzeugen.
Damit hatte mic@ schon von Hand begonnen, war aber noch nicht sehr weit gekommen. Mir war sofort klar, dass man diese Aufgabe mit überschaubarem Aufwand vollautomatisch erledigen kann. Die Datenbasis, nämlich die Datenbank hinter der Website opencaching.de, ist mit der sogenannten OKAPI-Schnittstelle automatisiert und maschinenlesbar abfragbar. Ich hatte die OKAPI zwar noch nie verwendet, aber ein wenig darüber gelesen. Für die grafische Darstellung von solchen Abhängigkeitsbeziehungen benutze ich seit vielen Jahren immer wieder gern Graphviz. Dies ist eine Opensource-Software, die darauf spezialisiert ist, aus abstrakten Beschreibungen von mathematischen Graphen – also Knoten und Kanten zwischen den Knoten – hübsche, für den Menschen anschauliche Grafiken anzufertigen.
Zwischen OKAPI und Graphviz war also nur noch ein Programm nötig, welches die erforderlichen Daten von opencaching.de abfragt und passend für Graphviz aufbereitet. Also habe ich mich hingesetzt und dieses Programm geschrieben. Als Implementierungssprache wählte ich die Skriptsprache Python, um mich mal wieder ein wenig darin zu üben – ich bin weit davon entfernt, fließend Python zu sprechen.
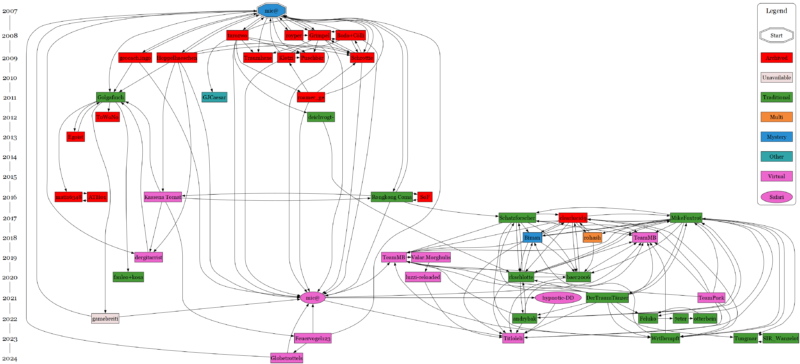
Verknüpfung aller Logs der Kettenreaktion-Caches
Gab es Schwierigkeiten während der Entwicklung?
Ja, aber zum Glück nur kleinere. Die erste Frage lautete: Was genau macht einen Cache überhaupt zu einem Kettenreaktionscache? Laut Anforderung von mic@ muss der neue Cache bestimmte Teile seines ursprünglichen Listings eins zu eins übernehmen, aber solch ein Kriterium ist gar nicht so einfach in einem Programm umzusetzen. Man stelle sich nur mal vor, das neue Listing enthalte sehr wohl alle geforderten Bausteine aus mic@s Listing, aber mit anderen Zeilenumbrüchen – ist das dann noch gültig? Zum Glück fordert mic@ einen bestimmten Namen für den Cache, nämlich “Kettenreaktion (Owner)”, was ich ein wenig aufgeweicht habe. Es muss nur das Stichwort “Kettenreaktion” irgendwo im Namen des Caches vorkommen. Wer als Owner allerdings in seinem neuen Cache-Namen das zusammengesetzte Wort “Kettenreaktion” mit Bindestrich schreibt, also “Ketten-Reaktion”, der hat verloren. Sein Cache würde von der Suche nicht erfasst.
Eine weitere Hürde war, dass bei OKAPI-Abfragen an manchen Stellen das Zeichen “senkrechter Strich” (auch bekannt als “pipe”) nötig ist. Das ist allerdings ein Sonderzeichen, welches in bestimmten Zusammenhängen nicht verwendet werden darf, sondern umschrieben (“escaped”) werden muss. Dies schien hier irgendwie automatisch zu geschehen: Ich benutzte den senkrechten Strich, es gab eine Fehlermeldung, in dieser stand etwas von “hier erwarte ich einen senkrechten Strich”, aber im weiteren Text der Fehlermeldung kam doch nicht der senkrechte Strich vor, sondern stattdessen eine Escape-Sequenz. Erst nach einer Rücksprache stellte sich heraus, dass hier die Dokumentation von OKAPI zu clever für mich war. Ich hatte die Doku per Internet-Suche gefunden und war bei der OKAPI-Dokumentation der polnischen Kollegen gelandet. In der polnischen Anleitung ist als Domainname “opencaching.pl” angegeben, was ich in meinem Code natürlich zu “opencaching.de” angepasst hatte und leider zu Fehlern führte. Benutzt man aber “www.opencaching.de”, also mit “www.” vorneweg, dann funktioniert es auch mit dem senkrechten Strich ganz wunderbar. Erst später habe ich entdeckt, dass man mit einem kleinen unscheinbaren Menü die OKAPI-Doku auf die jeweils gewünschte Sprache bzw. den gewünschten OC-Server einstellen kann. Sobald man also auf opencaching.de umgestellt hat, wird in den Beispielen völlig korrekt “www.opencaching.de” benutzt.
Eine andere Hürde besteht in der Komplexität der Opencaching-Datenbank. Ein Beispiel: Jeder Cache besitzt mindestens 2 Zeitstempel: den vom Anlegen und den von der Veröffentlichung. Normalerweise liegen zwischen den beiden nur ein paar Stunden oder Tage, es können aber auch Jahre sein. Welchen der beiden Zeitstempel soll man für den Stammbaum, der jahrgangsweise organisiert ist, benutzen? Bereits archivierte Caches tragen übrigens kein explizites archiviert-seit-Datum, sondern nur einen Archived-Log-Eintrag – oder eben auch nicht, warum auch immer! Außerdem ist es möglich, dass ein Cache mehrfach archiviert und wieder reaktiviert wurde. Wenn man all diese Details in den Grafiken berücksichtigen wollte, hätte man noch viel mehr zu tun, müsste also öfter Fallunterscheidungen und Kombinationen davon berücksichtigen – das habe ich mir mal gespart. Solcherlei Mehrdeutigkeiten gibt es noch an anderen Stellen. In jedem Fall musste ich mir einen Weg überlegen, damit umzugehen, und habe in aller Regel den einfachsten Weg gewählt.
Eine weitere Herausforderung habe ich mir vollkommen selbst eingebrockt:
Bei meinen Recherchen, die ich im Zuge der Programmierung angestellt habe, wurde ich noch auf Graphviz-Steps aufmerksam. Dieses Opensource-Programm beruht ebenfalls auf Graphviz, allerdings auf einer Neuimplementierung in Javascript. Damit ist es möglich, nicht nur einen fertigen, endgültigen Graphen darstellen zu lassen, sondern auch zu zeigen, wie sich dieser Graph schrittweise im Lauf der Zeit aufbaut. Das Anwachsen des Kettenreaktions-Stammbaums im Laufe der nun immerhin 18 Jahre kann man so sehr schick in einer Animation verfolgen. Leider erfordete das eine deutliche Umstellung in meinem Python-Code, der aber rasch bewerkstelligt war.
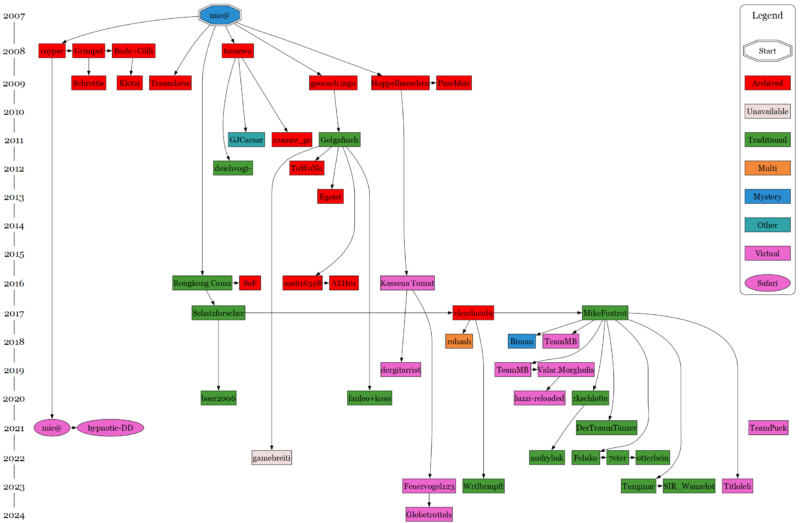
Verknüpfung der jeweils ältesten Logs der Kettenreaktion-Caches
Analyse (von Slini11)
Was liest jemand, der an der Konstruktion der Grafiken nicht selbst beteiligt war, denn nun heraus?
Und was zeigen die Grafiken nun und welche Schlüsse kann man daraus ziehen? Daran wagte sich nun Slini11:
Aktuell gibt es insgesamt 50 Kettenreaktion-Caches. Die obere Grafik zeigt dabei die Verknüpfung aller Logs der Kettenreaktion-Caches und die untere Grafik die Verknüpfung der jeweils ältesten Logs der Kettenreaktion-Caches – also die direkte Abstammung zwischen Mutter- und Tochter-Cache. Die Analyse basiert dabei überwiegend auf der unteren Grafik.
Zeitlinie
Klar erkennbar ist, dass alle Cache von Mic@s Ursprungcache aus dem Jahr 2007 ausgehen, welcher ganz oben dargestellt ist. Nachvollziehbarerweise sind die älteren Caches der Jahre 2008 bis 2013 überwiegend archiviert und die neueren Caches seit 2016 überwiegend aktiv. Interessant ist dabei, dass in den Jahren 2014 und 2015 kein einziger Kettenreaktion-Cache gelegt wurde, es also gewissermaßen eine Pause gab und sich die Kettenreaktions-Caches zeitlich in zwei große Generationen einteilen lassen. Die erste Generation von 2008 bis 2013 ist dabei mit 17 Caches deutlich kleiner als die zweite Generation von 2016 bis 2024 mit 33 Caches.
Cachetypen
Bei den Kettenreaktion-Caches sind die Typen Tradi und Virtual etwas gleich stark vertreten, während die Cachetypen Multi, Mystery und Other jeweils einmal vertreten sind. Schön ist auch, dass in der Grafik zusätzlich zwischen Virtual und Safari unterschieden wurde, wobei es nur zwei Safaris gibt.
Superspreader
Die Kettenreaktions-Grafik in den Listings beschreibt eine physikalische Kettenreaktion, bei der aus einer Aktion eine Vielzahl von Aktionen hervorgehen. Auch bei den Caches ist es so, dass manche Mütter-Caches mehr Tochter-Caches haben als andere. Mic@s Urspungslisting in Berlin hat z.B. sechs Tochtercaches hervorgebracht, ist damit aber nicht der Spitzenreiter. Dieser wurde von MikeFoxtrot in 2017 in München gelegt und hat schon acht Tochter-Caches – dies vermutlich auch aufgrund der guten Lage am Münchener Ostbahnhof. Den dritten Platz belegt Golgafinch mit seinem Muttercache im Norden von Berlin, aus dem vier weitere Caches hervorgingen.
Räumliche Aufteilung
Betrachtet man diese “Superspreader” und kennt die Cachernamen und deren Wohnort, fällt etwas auf: Es lässt sich dabei eine räumliche Verteilung feststellen und die Caches in räumlichen Clustern gruppieren.
Aller Ursprung ist Berlin, von wo die Kettenreaktion-Caches in den ersten Jahren die Hauptstadt bzw. deren Umgebung jedoch erstmal nicht verließen. Erste Ausbruchsversuche liefen über den Cache von Tarozwo, wo GJCaesar in der Schweiz und deichtvogt- in Hamburg jeweils eine Kettenreaktion legten, daraus jedoch bis heute keine neuen Caches entstanden.
Es dauerte bis 2017, als Schatzforscher nach einem Besuch in der Bundeshauptstadt einen Cache in München legte, aus dem fast 20 weitere Caches folgen sollten,, eben auch der Cache von MikeFoxtrot. Aus dem Münchener Cluster sind dann auch weitere Caches im Süden hervorgeganen, nämlich in der Schweiz und in Österreich. Außerdem hat sich nach einem Besuch in München von Feluko über dessen Cache in Frankfurt in Hessen ein weiteres kleines Cluster von drei Caches gebildet. Eine räumliche Ausnahme bildet der Cache von luzzi-reloaded in Tschernobyl sowie ein Safaricache in der Nordsee-Spirale.
Die obere Grafik aller Logs zeigt die räumliche Verteilung sogar nochmal etwas deutlicher, da hier alle Logs miteinander verknüpft sind. So ist es wahrscheinlicher, dass Caches, die räumlich nah beieinander liegen, gegenseitig häufiger geloggt werden, was durch die obere Grafik auch bestätigt wird. Somit lässt sich ein Großteil der Caches – auch ohne Karte – Anhang der Diagramme von rkschlotte wirklich gut räumlich clustern. Die folgenden Karten bestätigen die räumliche Clusterung:

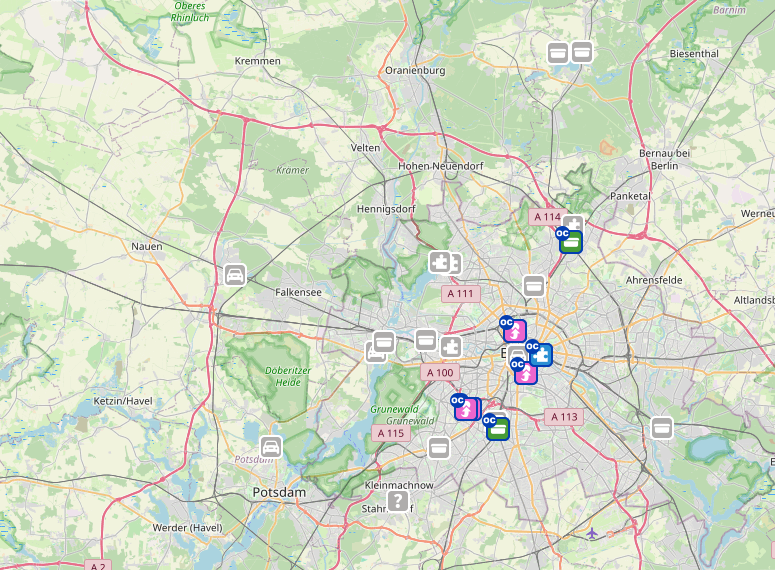
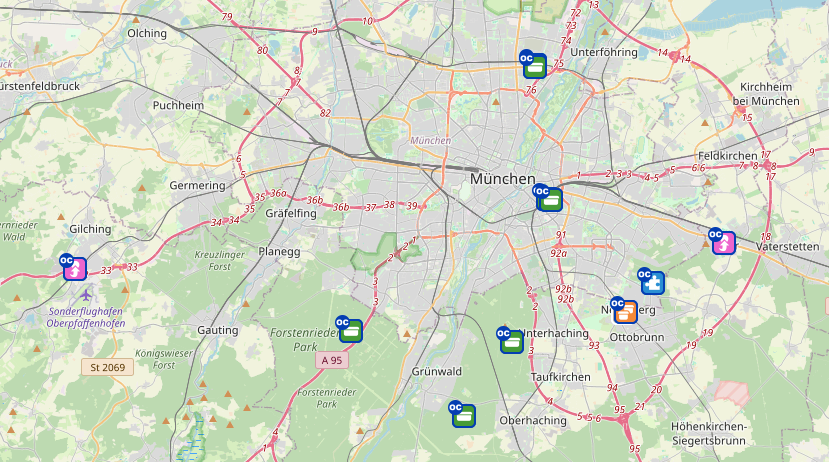

Spannend wäre sicherlich ein Mix aus den Grafiken von rkschlotte verknüpft mit einer Karte, um dort den räumlichen Verlauf der Caches nachvollziehen zu können.
Eine Übersicht der Cluster gibt es hier als Cacheliste:
Fazit (von rkschlotte)
Insgesamt habe ich schätzungsweise 30 Stunden in die Programmierung und die Tests investiert – und ich habe einiges gelernt :-)
Herausgekommen sind knapp 500 Zeilen Code in zwei Skripten; aus praktischen Gründen habe ich die OKAPI-Abfragen und das Erzeugen der Grafiken voneinander getrennt. Ich habe keine konkreten Pläne zur Weiterentwicklung, aber wenn jemand noch eine Idee hat, bin ich gern bereit, diese zu prüfen. Was ich sehr wohl vorhabe, ist, das Programm gelegentlich nochmal laufen zu lassen, um zu schauen, was sich bei den Kettenreaktions-Caches so tut: Welche werden archiviert (hoffentlich wenige) und welche kommen neu hinzu (hoffentlich viele)?
Tungmar
Das ist eine tolle Übersicht über die Kettenreaktion! Vielen Dank! Auch für die ganze Beschreibung wie das so entstanden ist. Ich gespannt wie sich die Cacheserie weiter entwickelt und ob wir da noch ein paar in die Schweiz kriegen :-D
Gibt es den Code der die Grafiken erstellt irgendwo als (open source) zum anschauen?